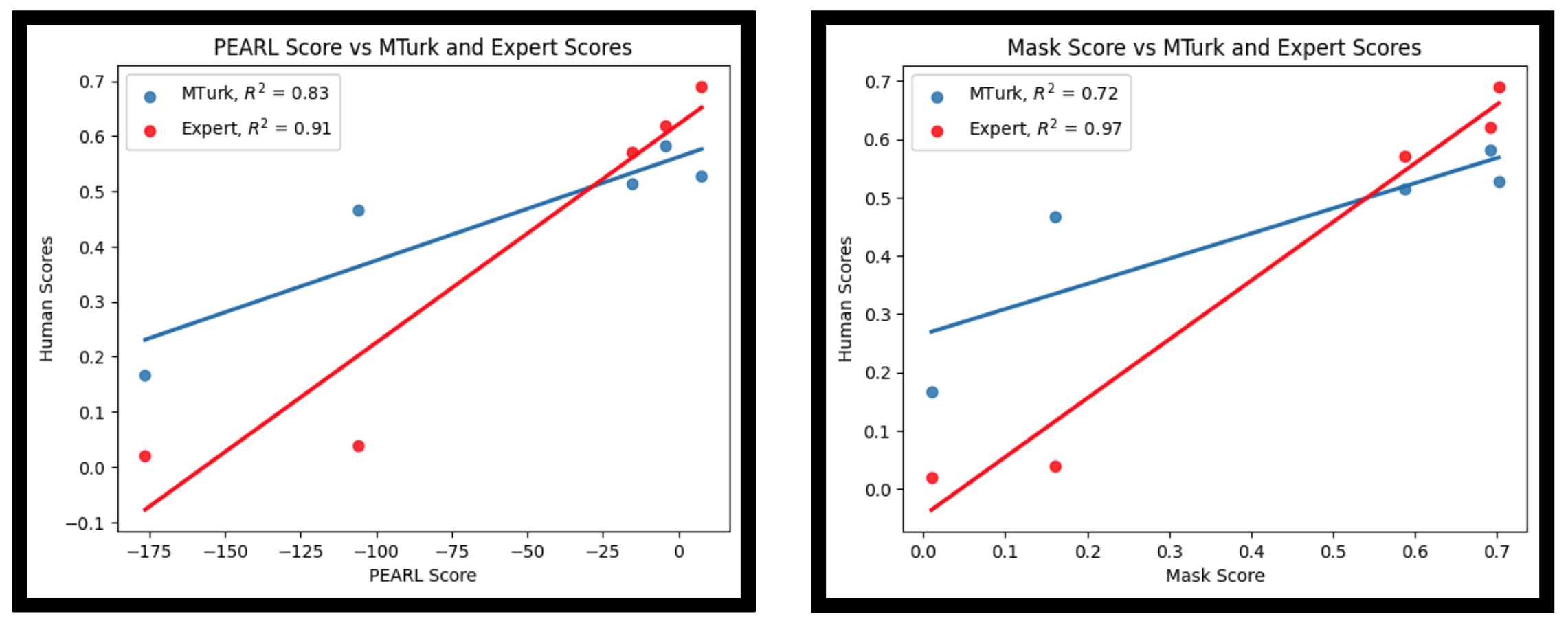
Scores on various methods on PEARL benchmark.
| # | Tagger | Filter | Selector | Locator | In Mask | Score | MTurk | Expert |
| - | Natural Placement* | 0.907 | 17.987 | 1.000 | 1.000 | |||
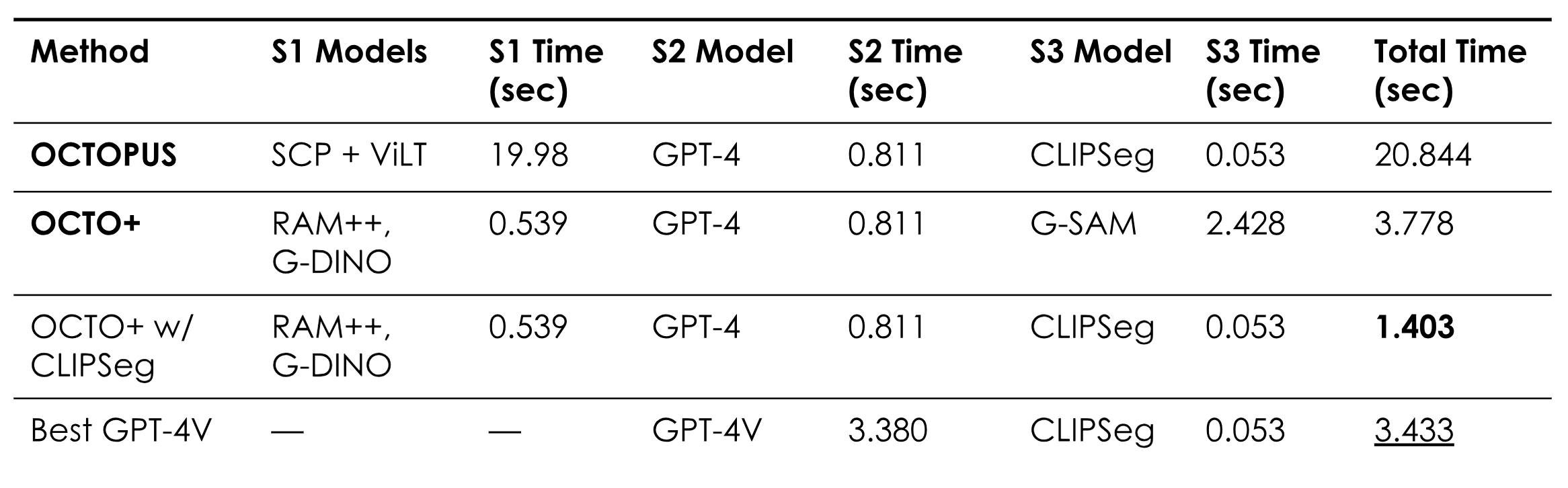
| 1 | RAM++ | G-DINO | GPT-4 | G-SAM (Center) | 0.702 | 7.634 | 0.527 | 0.690 |
| 2 | GPT-4V(ision) | CLIPSeg (Max) | 0.692 | -4.492 | 0.582 | 0.620 | ||
| 3 | GPT-4V(ision) | G-SAM (Center) | 0.686 | 4.317 | 0.580 | - | ||
| 4 | RAM++ | G-DINO | GPT-4 | CLIPSeg (Max) | 0.671 | -4.185 | 0.547 | - |
| 5 | LLaVa-v1.5-13B | CLIPSeg (Max) | 0.649 | -13.17 | - | - | ||
| 6 | SCP | G-DINO | GPT-4 | G-SAM (Center) | 0.615 | -6.464 | - | - |
| 7 | SCP | CLIPSeg | GPT-4 | G-SAM (Center) | 0.613 | -10.783 | - | - |
| 8 | SCP | G-DINO | GPT-4 | CLIPSeg (Max) | 0.596 | -13.005 | - | - |
| 9 | SCP | ViLT | GPT-4 | CLIPSeg (Max) | 0.588 | -15.300 | 0.514 | 0.570 |
| 10 | SCP | CLIPSeg | GPT-4 | CLIPSeg (Max) | 0.572 | -20.730 | - | - |
| 11 | GPT-4V (Pixel Location) | 0.321 | -34.282 | - | - | |||
| 12 | InstructPix2Pix | G-SAM (Bottom) | 0.283 | -60.852 | - | - | ||
| 13 | Random Placement* | 0.161 | -106.113 | 0.467 | 0.040 | |||
| 14 | Unnatural Placement* | 0.010 | -176.375 | 0.167 | 0.020 | |||